La croissance effrénée de la quantité de textes utilisés pour l'entraînement des modèles LLM soulève une question inédite : risque-t-on de manquer de données textuelles pour entraîner les prochains modèles ? Des chercheurs estiment en effet que le volume de texte public disponible n’est pas infini. Internet constitue une gigantesque bibliothèque, mais « pas une source inépuisable ».
Les dix dernières années ont vu une croissance vertigineuse des données utilisées pour entraîner les modèles de langage en intelligence artificielle (IA). En l’espace d’une décennie, on est passé de quelques milliards à des dizaines de milliers de milliards de tokens pour préentraîner les modèles de langue (figure 1).
Les tokens, petits fragments textuels constitués sur la base de phonèmes, graphèmes, morphèmes et autres caractères spéciaux, sont extraits la plupart du temps à partir de vocabulaires textuels humains, pour faciliter l'entraînement des modèles en IA générative. Le « perroquet stochastique » [11] que constitue l'IA générative se base ainsi sur les relations existantes, entre ces bouts de mots, dans des quantités énormes de corpus de texte humain, pour recracher de manière probabiliste des séquences de mots en fonction des statistiques d’occurrence, sans réelle compréhension sémantique.
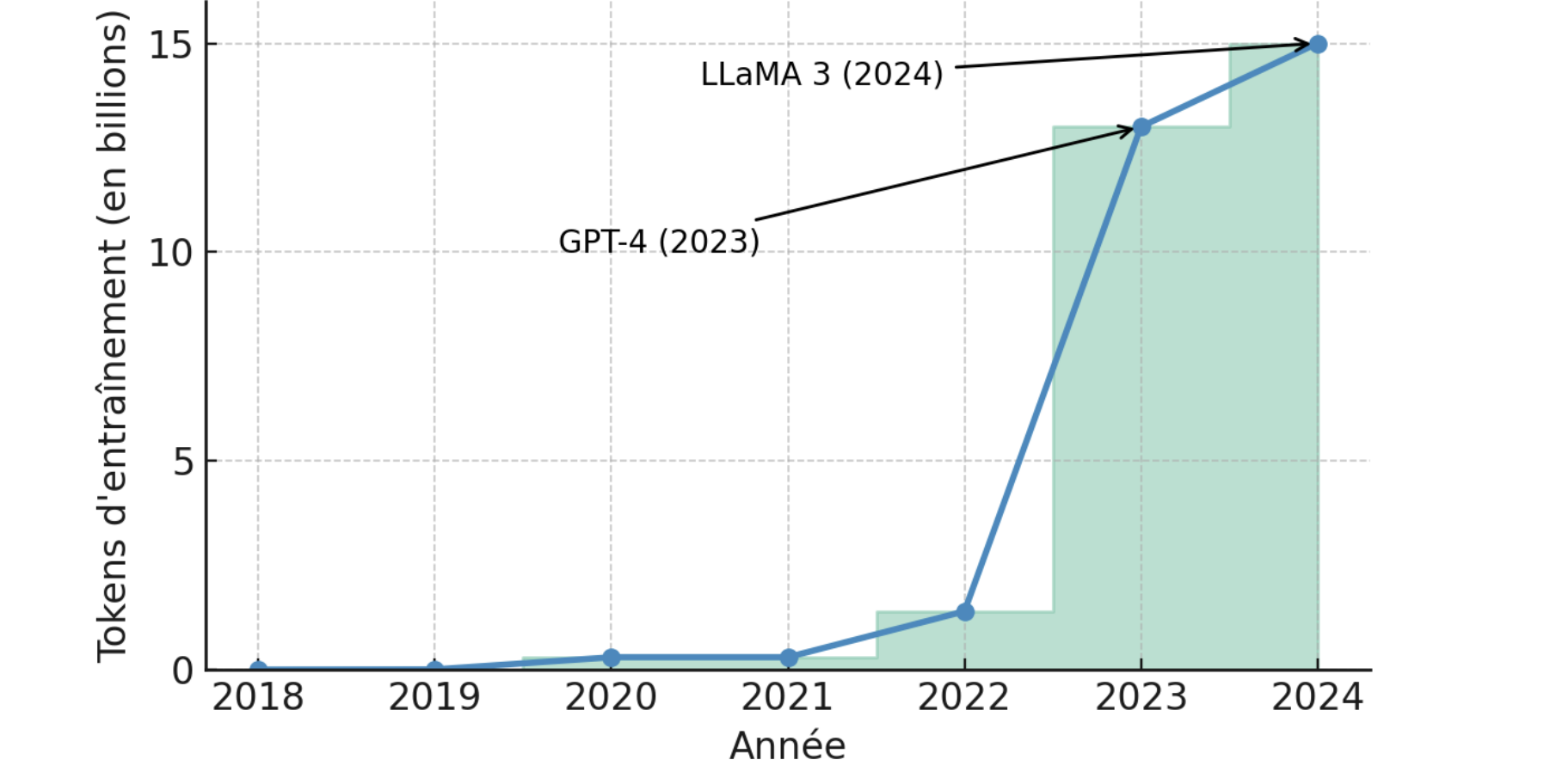
Figure 1. Évolution estimative du volume de tokens utilisé pour l'entraînement des modèles LLM durant ces six dernières années. Chaque point correspond à un modèle marquant son époque, illustrant la croissance fulgurante en "tokens" utilisés.
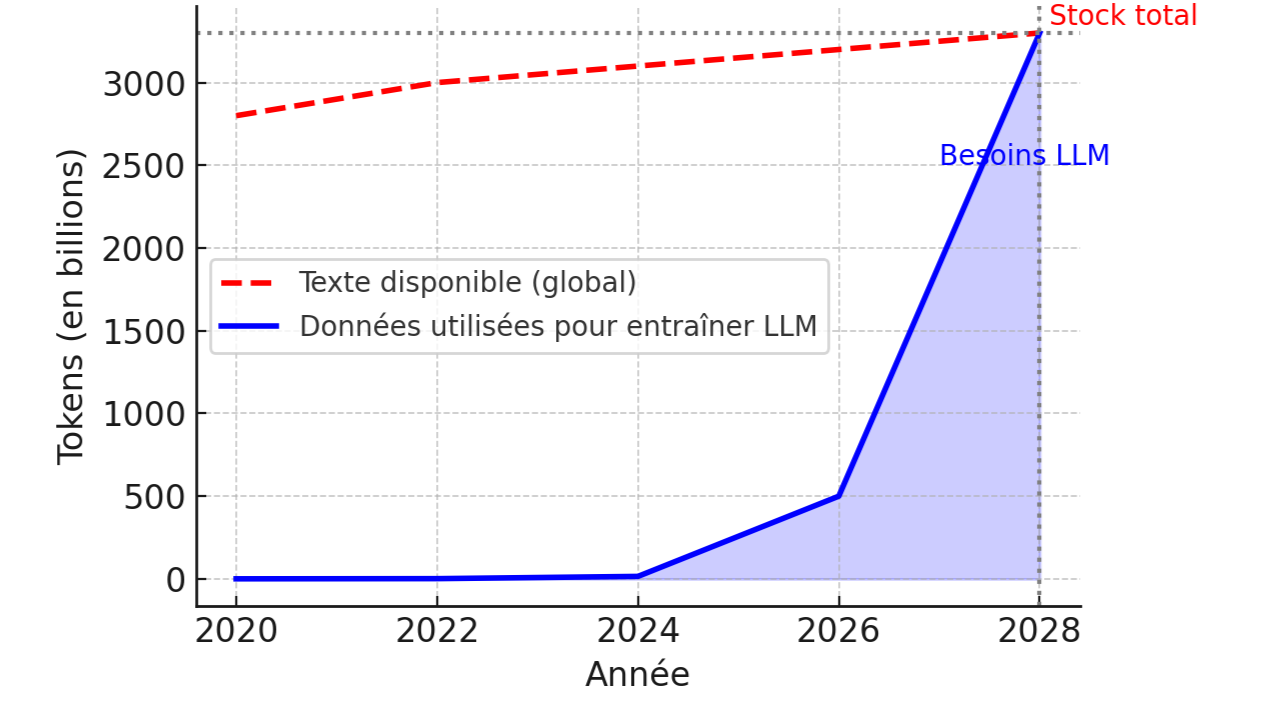
Une étude prospective de l’institut Epoch a quantifié le problème : au rythme actuel, les ensembles de données d’entraînement pourraient atteindre la taille de tout le stock de texte disponible en ligne d’ici 2026–2028 [1][2]. En d’autres termes, les modèles géants comme GPT puisent si vite dans le contenu du web qu’ils auront bientôt tout lu (figure 2).
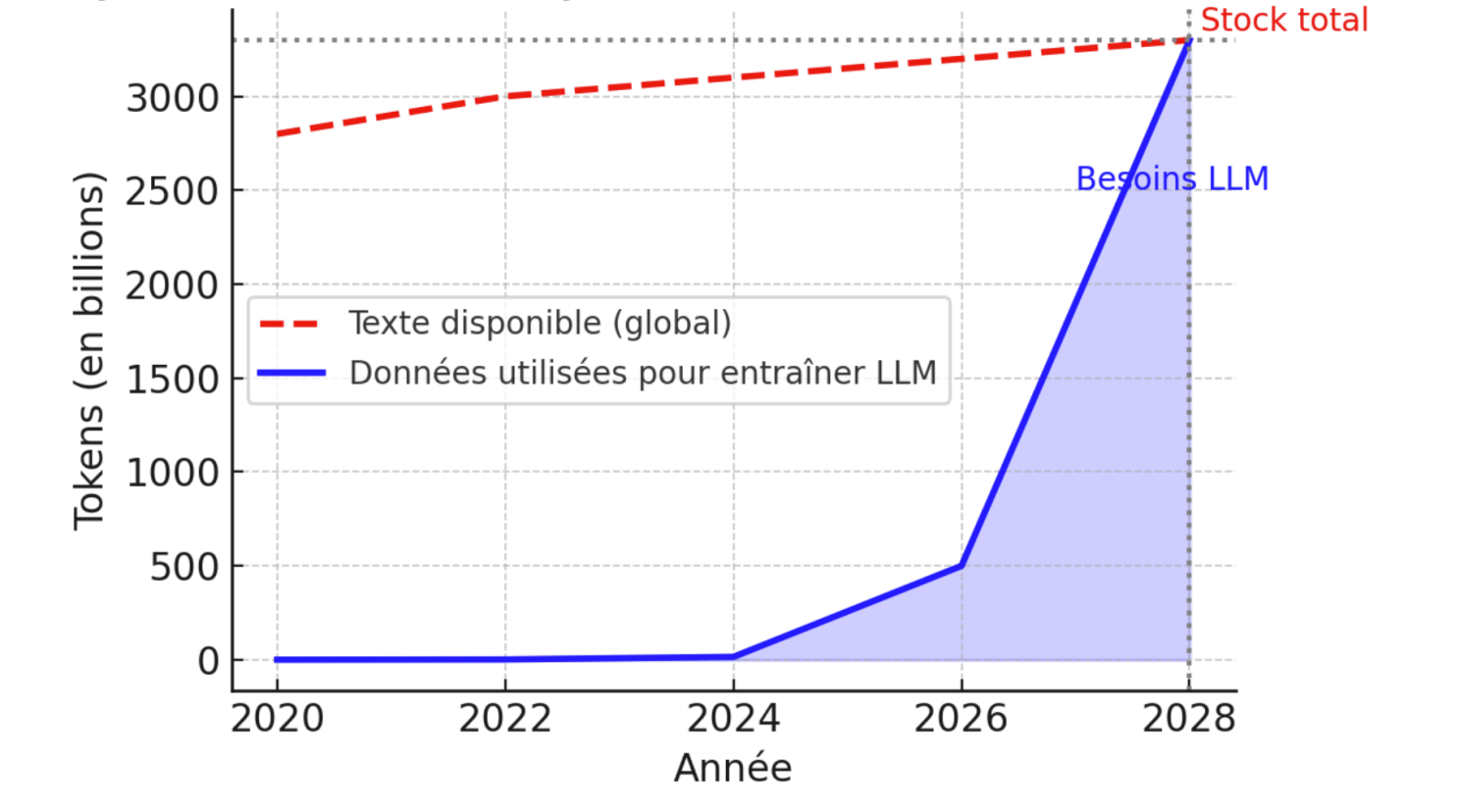
Figure 2. Projection illustrative du volume de texte utilisé pour entraîner les LLM, comparé au stock total de texte humain disponible en ligne. SI les tendances se poursuivent, les deux courbes pourraient se rejoindre vers 2028.
On estime le stock global de texte humain accessible sur Internet à environ 3 100 billions de tokens [1]. Ce stock augmente relativement lentement (quelques % par an, à mesure que sont publiés de nouveaux articles, livres, posts…), tandis que la quantité de données ingérées par les LLM double tous les un à deux ans [1].
La convergence de ces courbes est illustrée en figure 2. Dès 2023, OpenAI reconnaissait ce « mur de données » : le PDG Sam Altman a admis que simplement entraîner des modèles plus grands sur toujours plus de données « touche à sa fin », et qu’il faudra trouver d’autres approches [2].
De plus, la qualité des données restantes pose question : une grande partie du web est constituée de textes à faible valeur (données dupliquées, contenu spam, textes générés automatiquement, etc.) qui sont volontairement filtrés lors de l’entraînement. Les textes vraiment utiles – bien écrits, informatifs et diversifiés – sont bien plus rares.
Certaines langues, peu présentes en ligne, sont gravement sous-représentées dans les corpus actuels (par ex. le français < 0,2% des données de LLaMA 2) [3].
Enfin, des barrières juridiques commencent à se dresser : éditeurs de presse, auteurs et autres ayants droit cherchent à restreindre l’utilisation de leurs contenus protégés par les IA, via des procès retentissants (Reuters, OpenAI, Meta… sont visés en 2023-2024).
Tous ces facteurs laissent craindre un futur plateau dans le progrès des LLM, faute de carburant textuel frais [2]. Les géants du secteur planchent donc sur des alternatives : génération de données synthétiques (créer du texte artificiel pour compléter les données humaines), exploitation de formats jusqu’ici peu utilisés (par ex. transcrire en texte des vidéos, des enregistrements audio, etc.), ou encore amélioration de la qualité plutôt que de la quantité des données [1]. Quoi qu’il en soit, nombre d’experts appellent à redoubler d’ingéniosité pour éviter une « famine de données » à l’ère de l’IA [4][5].
L’offensive des bibliothèques et de l’open data comme nouvelles sources de données
Des initiatives récentes visent à augmenter le stock de données d’entraînement disponibles : numérisation de livres anciens, mise à disposition de données publiques, etc.
Exemples :
le projet RedPajama-2 a publié un corpus web de 30 000 milliards de tokens, surpassant en volume tous les corpus publics précédents ;
RefinedWeb a extrait 5 000 milliards de tokens de Common Crawl pour entraîner Falcon ;
Google a numérisé ~20 millions de livres (5 000 milliards de tokens, dont une partie désormais libre de droits) ;
le corpus multilingue de BLOOM (~340 milliards) et le nouveau jeu de Harvard (242 milliards) complètent l’existant.
Le graphique de la figure 3 nous donne une illustration estimative des récentes initiatives augmentant le stock de données d'entraînement des modèles LLM.
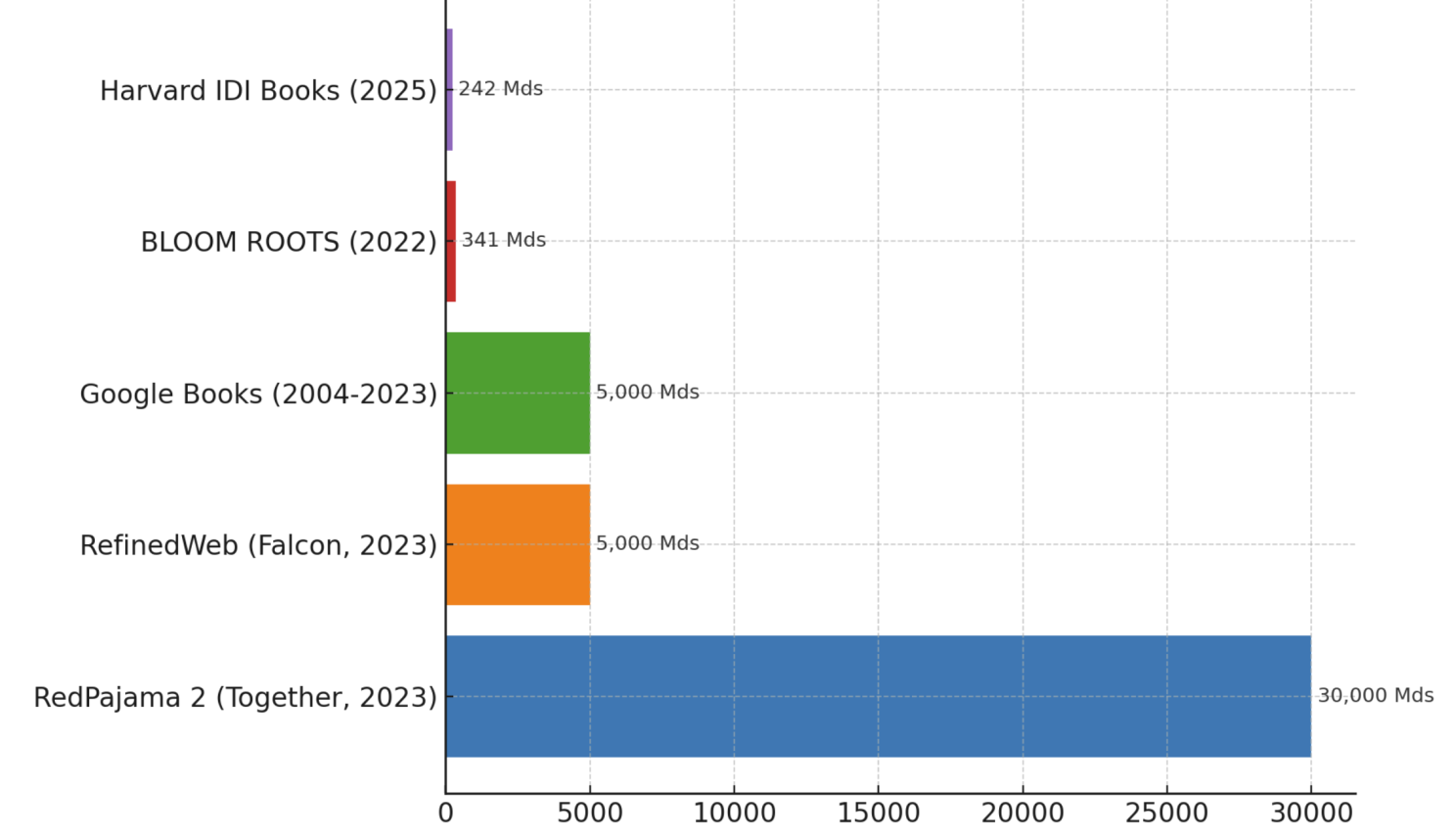
Figure 3. Illustration estimative des récentes initiatives augmentant le stock de données d'entraînement
L’enjeu est crucial : incorporer ces données fraîches et diversifiées pourrait nourrir la prochaine génération de LLM tout en atténuant la dépendance aux données du web anglophone.
Qu'en est-il de l'Afrique?
En parallèle, la question de la diversité linguistique est cruciale : la quasi-totalité de ces données massives concerne une poignée de langues (anglais dominant, chinois, français, arabe…), tandis que des milliers de langues – notamment africaines – sont très peu présentes en ligne.
L’Afrique compte plus de 2000 langues [6] (du swahili au haoussa en passant par l’amharique, le yoruba, le peul, etc.), dont beaucoup sont parlées par des millions de personnes mais restent presque absentes des grands corpus numériques.
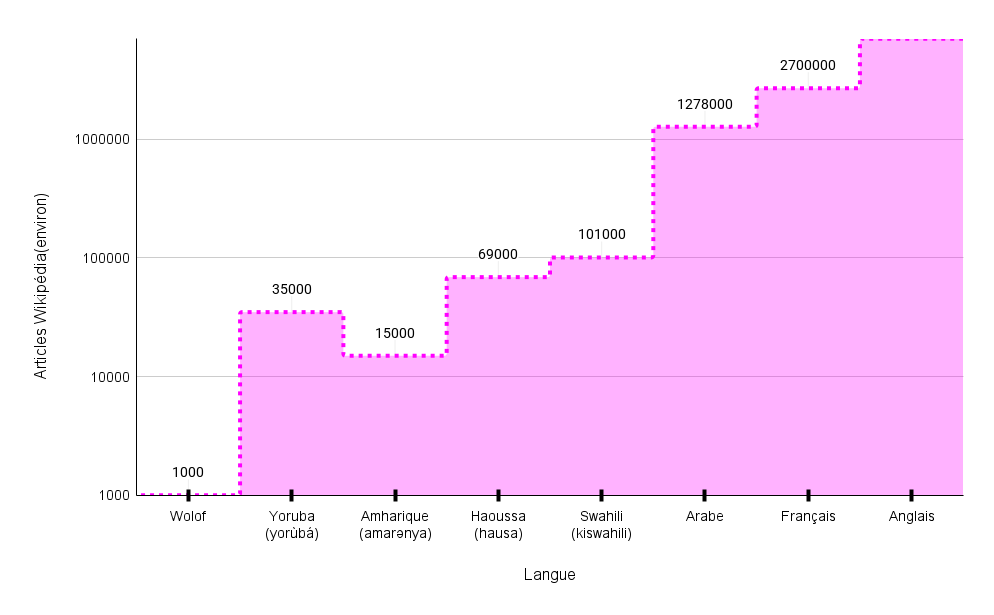
Figure 4. Estimation de la disponibilité d'articles Wikipédia sur différentes langues
En guise d'exemple, le swahili et le haoussa cumulent plus de 150 millions de locuteurs et ne comptent tous les deux que moins de 200 mille articles Wikipédia [8], contre plus de 7 millions pour l’anglais (figure 4). De même, les textes de presse disponibles en langues africaines ainsi que les livres se comptent en quelques milliers seulement [9] (figure 5 et 6).
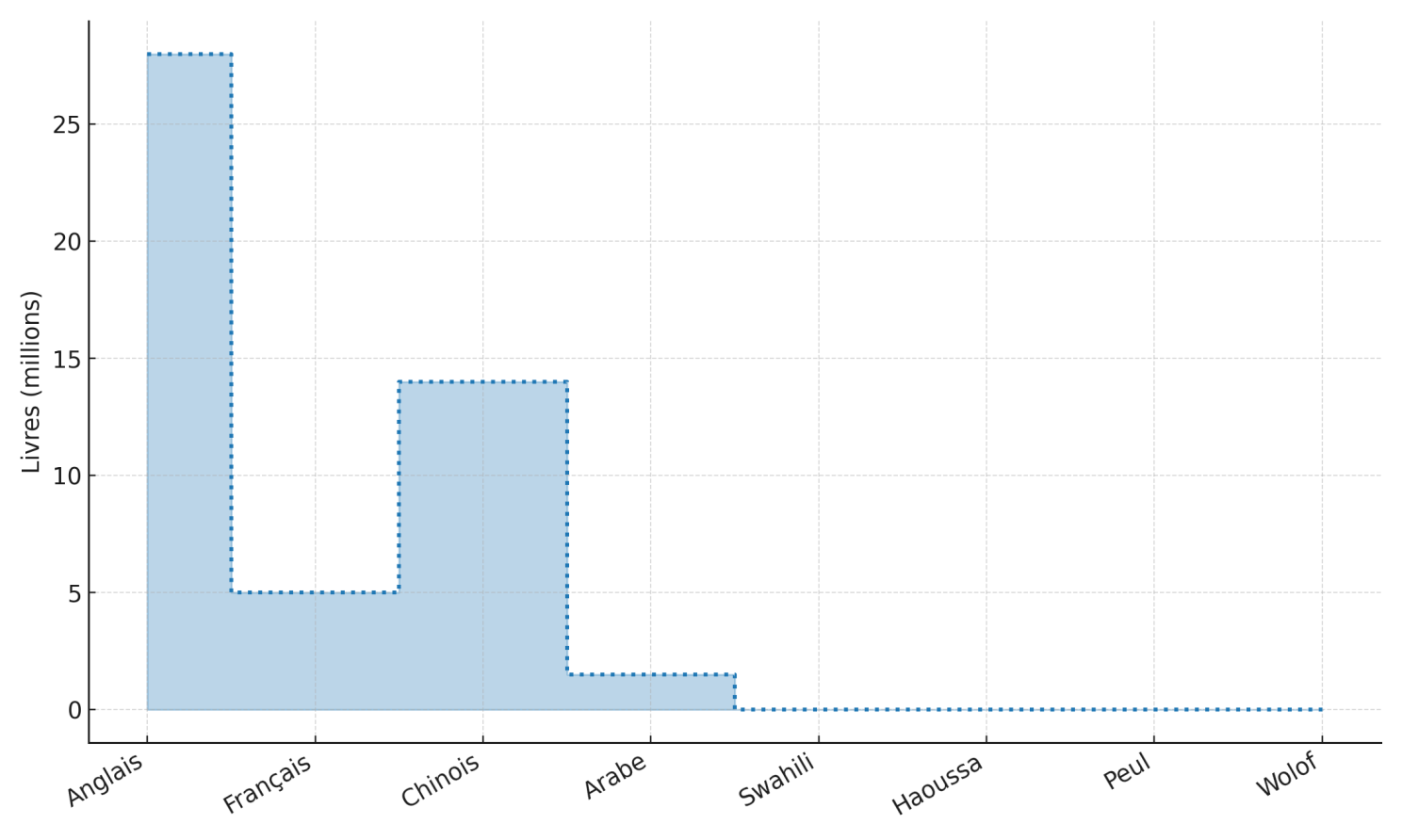
Figure 5. Estimations de la disponibilité des livres sur différentes langues
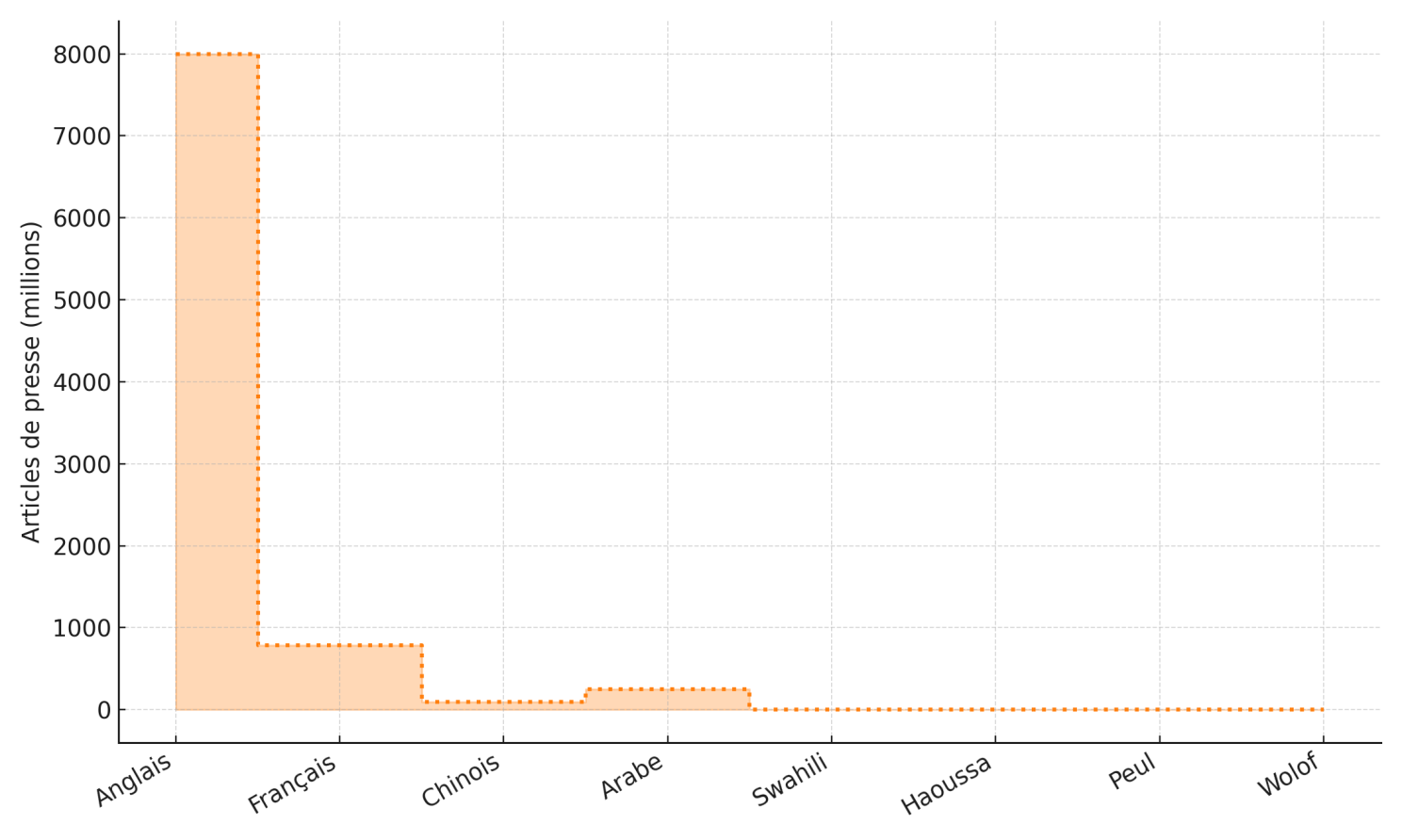
Figure 6. Estimation de la disponibilité des articles de presse sur différentes langues
Cette sous-représentation s’explique par des défis techniques (claviers et encodage pour certains alphabets, outils NLP (Natural Language Processing) entraînés surtout sur l’anglais, manque d’investissements) et historiques (langues longtemps marginalisées à l’écrit pendant la colonisation [9]).
Néanmoins, des initiatives émergent pour combler ce fossé :
le mouvement Masakhane – « nous construisons ensemble » en zoulou – fédère une communauté panafricaine pour développer les données et outils NLP dans les langues africaines [9];
l’African Language Technology Initiative (ALTI) ou des projets comme Lacuna Fund financent la constitution de corpus et de jeux de données ouverts (par ex. corpus de parole en igbo, hausa et yoruba, données de traduction pour des langues du Kenya, [10]);
plus de 62 640 ouvrages et manuscrits conservés à la bibliothèque de l’IFAN de Dakar, où un labo de numérisation a été installé au WARC (West African Research Center), et des initiatives internationales comme l’ELAR (Endangered Languages Archive) qui collectent des heures d’enregistrements audio en langues menacées, mais dont les données restent largement non structurées pour un usage direct en IA.
En outre, les langues africaines possèdent des corpus oraux très riches, mais restent peu numérisés. L'exploration de nouveaux paradigmes techniques (algorithmiques) alternatifs aux approches « d'entraînement de modèles plus grands sur plus de données », pourrait contrebalancer les défis techniques liés à l'absence de données textuelles sur les langues africaines.
Ces efforts, soutenus parfois par de grands acteurs (ex. Google, Mozilla, etc.), visent à préserver la diversité linguistique et à permettre aux locuteurs africains d’accéder aux applications d’IA dans leur langue maternelle.
En somme, l’ère des LLM se caractérise par une frénésie de données textuelles – une course aux trillions de tokens – tout en révélant l’urgence de mieux intégrer toutes les langues du monde, notamment africaines, afin que les futurs modèles soient vraiment inclusifs et représentatifs de la diversité humaine.
Sources & références
- [1] Jones, Nicola. “The AI Revolution Is Running Out of Data. What Can Researchers Do?” Nature, 11 Dec. 2024. DOI: 10.1038/d41586-024-03990-2. Consulté le 8 sept. 2025.
- [2] Mok, Aaron. “Data Is Fueling the AI Revolution. What Happens When It Runs Out?” California Magazine, 20 Mar. 2025. Consulté le 8 Sept. 2025.
- LINAGORA. “Zoom sur les datasets d’apprentissage : vers des données plus « propres ». Consulté le 8 Sept. 2025.
- [4] Bordoloi, Satyen K. “The Great Data Famine: How AI Ate the Internet (And What’s Next).” Sify, 13 Jan. 2025. Consulté le 8 Sept. 2025.
- [5] Villalobos, Pablo, et al. “Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data.” Epoch, 6 June 2024. Consulté le 8 Sept. 2025.
- [6] Stanford SIPR (2023). African Missing Languages in the Digital World.
- [7] “Top 10 Most Spoken Languages in Africa.” Talk Africana. Consulté le 10 sept. 2025.
- [8] Wikimedia Foundation. “African Languages.” Meta-Wiki. Consulté le 10 sept. 2025.
- [9] Adelani, David, Israel Orife, Chiamaka Emezue, et al. “MasakhaNEWS: A Dataset for Multilingual African News Classification.” Hugging Face Datasets, 2020. Consulté le 10 sept. 2025.
- [10] Lacuna Fund. “African Language Awardees 2021.” Lacuna Fund, 2021. Consulté le 10 sept. 2025.
- [11] Bender, E. M., Gebru, T., McMillan-Major, A., & Mitchell, M. (2021). "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" (présenté à la conférence FAccT 2021 – ACM Conference on Fairness, Accountability, and Transparency).